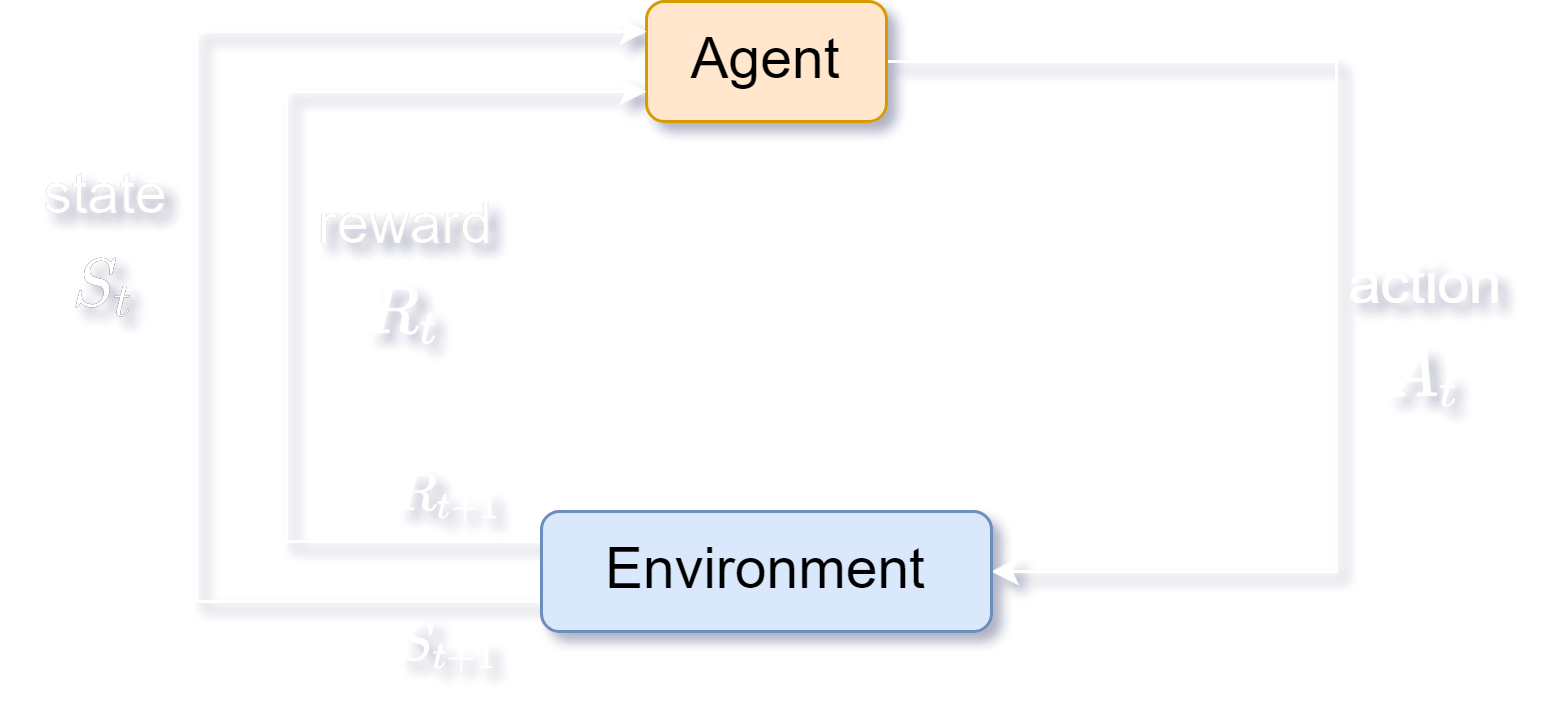
Consider an agent in an environment with state , where the agent can choose to select an action , and the environment responds with a reward and a new state.
, , and denote the state, reward given, and action taken at time .
Markov Property
An environment has the Markov Property if and only if the next state of the system depends only on the current state and the current action , and not on past states or actions.
Policy
The policy at step is the probability of choosing action at state .
Episodic & Continuing Tasks
Episodic tasks are ones that have finite steps and a terminal state.
Continuing tasks are ones that do not end or have a terminal state,
Return
Given the rewards given to the agent, the return is the expression we aim to maximize at any step.
Total Reward
Discounted Reward
Value & Action-Value Functions
The value function of a state under a policy is the expected return when starting in state and following hereafter:
The value function of a state under a policy is the expected return when starting in state , choosing action , and following thereafter: